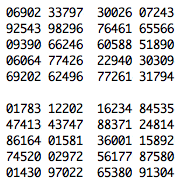
Since the RAND Corporation seems to take the position that their canonical table of random digits is their property,1 here is a drop-in replacement. The formatting and statistical properties of these digits are identical, but the numbers themselves are independently generated.
Unlike the RAND Corporation, I concede that there is no creative content in these tables and therefore they are uncopyrightable. I further dedicate any copyright interest I may have in these tables to the public domain (although I do not believe that there is any copyright interest for me to relinquish). You may redistribute, modify, or use these tables for any purpose whatsoever.
Update: I have discovered that the copyright—such as it is—has lapsed on 21,875 of these digits. Enjoy.
The random digits were generated by taking bytes off of /dev/urandom on an iMac G4 running Mac OS 10.4.8, discarding those greater than 249, and keeping the last digit. Finally, the resultant million digits were added modulo 10 to the canonical RAND digits, ensuring that they are no less random.
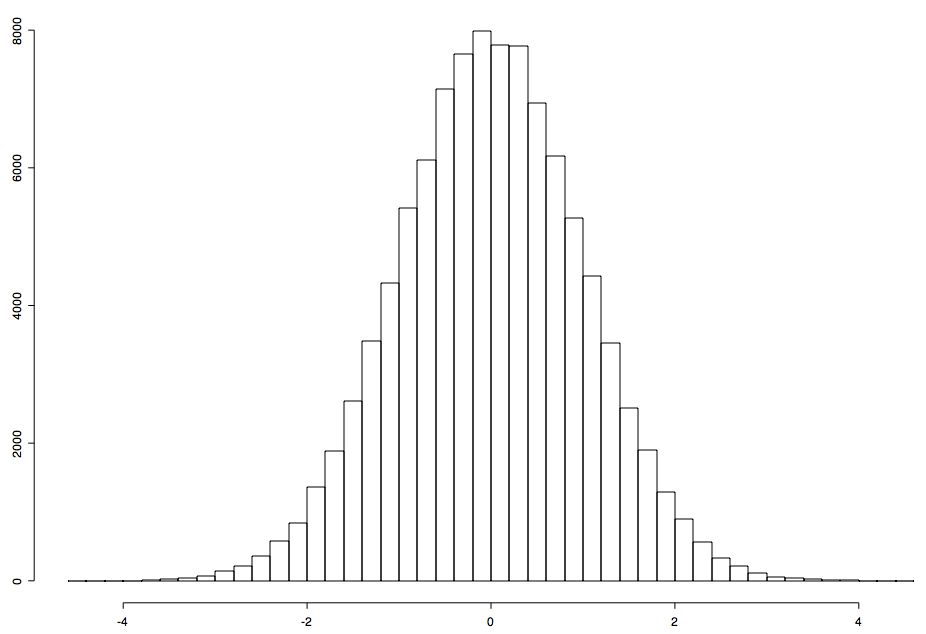
The original normal deviates (deviates.txt) were computed with a different technique from RAND and are not related to the digits. The entropy source for these was /dev/urandom on the same machine, XOR'ed against random bytes from random.org. Slightly more than 8 bytes of entropy are used per deviate in a simple rejection technique. Random integers are converted to double-precision floats in the range [0,1) by dividing the thirty-two bit integers by 2^32. Darts are thrown at the normal probability density function from -5 to 5 by selecting a pair (x, y) = (10*random_double() - 5, random_double()). If the dart lands beneath the curve, e.g. y < (1/√ 2π )e-x2/2, the x value is kept as the deviate, otherwise, it is discarded. There is no detectable bias from eliminating the tails beyond 5 standard deviations because no deviates this extreme can be expected in a sample size of 100,000.
Note: I have recovered the original source used to compute this set of deviates: deviates.c
The second set of normal deviates (deviates2.txt) were derived from half of the random digits using the same method as the RAND deviates. Specifically, a five digit block D is used to compute one deviate by using the formula √ 2 erf-1(2(D + 0.5)10-5 - 1). (erf-1 is the inverse error function.) The left-hand five columns of the digits are used to compute the deviates in the following manner: The first 10,000 rows of the first column of digits are used to compute the first column of deviates, the second half of the first column of digits is used to compute the second column of deviates and so on (column 2 of digits yields column 3 and 4 of deviates, etc.).
0 100518 1 100083 2 99870 3 100215 4 99761 5 99704 6 99589 7 100084 8 99803 9 100373This distribution has a Χ2 value of 8.37 with 9 degrees of freedom, with a probability of 0.497.
Use of the second set of deviates, calculated using the same method as the RAND Corporation for their 100,000 deviates, cannot be recommended except where identical statistical properties to the RAND table or its correlation to the random digits is required. The reason is that the RAND deviates contain a readily-apparent bias in the tails, because the five digit integer input does not contain enough significant digits to cover the 4 significant digits of the output. While RAND did perform a separate analysis on the tails of their deviates, it was not careful enough to uncover the bias which becomes immediately apparent from looking at the integer → deviate map:
D → √ 2 erf-1(2(D + 0.5)10-5 - 1)
00000 → -4.417
00001 → -4.173
00002 → -4.056
00003 → -3.976
00004 → -3.916
00005 → -3.867
00006 → -3.826
00007 → -3.791
00008 → -3.760
00009 → -3.732
00010 → -3.707
...
99989 → 3.707
99990 → 3.732
99991 → 3.760
99992 → 3.791
99993 → 3.826
99994 → 3.867
99995 → 3.916
99996 → 3.976
99997 → 4.056
99998 → 4.173
99999 → 4.417
With a sample size of 100,000 deviates, each 5-digit block is expected to occur once on average. The result is that each of the above deviates is produced on average once in a sample of 100,000 deviates generated by this method—and no others in this range. So both the RAND deviates and deviates2.txt contain multiple instances of 4.417, as well as other deviates listed above, but no deviates in the gaps from 4.174-4.416, 4.057-4.172, etc., an obvious bias. Since 4.3... is expected but can never be emitted, the RAND technique using only 5 digits of input has detectable bias at the tails even at one decimal place. The RAND analysis of the tails (Table 8 of the introduction) looks only at bins with an expected value of 25, which is not sensitive enough to detect this bias.
From: XXXXXX To: Nathan Kennedy Sent: October 3, 2006 8:52 AM Subject: RE: Question regarding A Million Random Digits <snip> You are incorrect in your assumption that you this material is not subject to copyright law. RAND is the copyright holder, and we do not grant the right for others to distribute the info. <snip> -----Original Message----- From: Nathan Kennedy Sent: Monday, October 02, 2006 11:02 PM To: XXXXXX, RAND Corporation Subject: Question regarding A Million Random Digits Dear XXXXXX, I have a question regarding the RAND Corporation publication "A Million Random Digits with 100,000 Normal Deviates." I would like to utilize these tables and redistribute them on the Internet. It is my understanding that the numerical tables of random digits and normal deviates themselves contain no creative content and therefore are not subject to copyright or the property of RAND Corporation (obviously the prefatory materials are, and these would be excluded). However, before I widely redistribute these tables I wanted to make sure that this is in line with the RAND Corporation's view, and that the RAND Corporation will not challenge any third party's right to utilize these tables as they see fit. Thank you for this useful resource and for looking into this, Nathan Kennedy